

En Memphis, Tennessee, en lo que una vez fue una planta de electrodomésticos de Electrolux, hoy vive Colossus: un clúster de más de cien mil GPUs H100, expandiéndose hacia el medio millón de aceleradores y varios gigavatios de potencia instalada cuya misión es entrenar a Grok y sus próximas versiones. Al mismo tiempo Elon Musk ejecuta su próximo movimiento estratégico fusionando a SpaceX con xAI, consiguiendo así tener los mejores cohetes, satélites, redes, supercomputadoras y modelos de IA bajo un mismo envoltorio.
La compra de xAI por parte de Space X no es un movimiento arbitrario. Esta unión permite crear un sistema físico‑digital donde la física dura de SpaceX alimenta los gradientes de xAI, y viceversa. Y con esto Musk puede avanzar con un plan mucho más ambicioso y completamente futurista, desplegar hasta un millón de satélites‑data center en órbita baja, alimentados por energía solar y enlazados por láser que se convertirán en los complementos y eventualmente sustitutos de Colossus para dar vida a las próximas generaciones de modelos de inteligencia artificial.

Suscríbete para que juntos destapemos las cajas negras y descubramos lo que ocultan.
Cuando los LLMs tocan la realidad
La mayoría de los modelos fundacionales que usamos hoy —GPT‑4, Claude, Gemini, el propio Grok 3/4— viven en el espacio abstracto de los tokens. Se entrenan sobre:
Texto a escala planetaria (web, libros, código, papers).
Datos sintéticos generados por modelos más pequeños o versiones anteriores.
Feedback humano o de modelos críticos para alinear salidas.
La “física” que aprenden está mediada: ecuaciones en LaTeX, gráficos de papers, descripciones de maniobras, no fuerzas, temperaturas o vibraciones medidas in‑situ. Un LLM sabe escribir la ecuación del drag o aproximar una órbita, pero no ha visto el stream crudo de datos que produce un cohete en ascenso supersónico o un satélite en degradación orbital.
Al fusionar SpaceX y xAI, esa separación deja de ser estructural. Pasa de ser:
mundo físico → herramientas internas de análisis → resumen humano → texto → modelo de lenguaje
a algo más corto:
mundo físico → pipeline de datos de SpaceX/Starlink → modelos especializados → Grok
Las fuentes de datos que se vuelven accesibles (al menos potencialmente) son cualitativamente distintas de las que alimentan a cualquier otro actor de IA:
Telemetría de cohetes y naves: Falcon 9, Falcon Heavy, Starship, Crew Dragon. Señales GN&C, presiones, temperaturas, vectores de aceleración, health de motores, estado del TPS, etc.
Telemetría de satélites y red: constelación Starlink (y Starshield), con métricas de SNR, beam‑forming, interferencias, congestión de enlaces, routing dinámico sobre ISLs ópticos.
Tráfico de soporte y operación: logs de interacción entre usuarios y soporte técnico de Starlink y Tesla, que ya están mediadas por Grok como primer nivel de atención.
Un punto clave reciente: Starlink actualizó en enero de 2026 su política de privacidad para permitir usar datos de clientes —salvo opt‑out— en el entrenamiento de modelos de IA, y medios como Reuters vinculan explícitamente este cambio a la fusión con xAI.
🕵️♂️ The Hidden Layer: Los datos de red y operación dejan de ser solo métricas internas y se convierten en combustible explícito para modelos. Por lo qué xAI es, hoy, el único laboratorio de LLMs con acceso directo y continuo a flujos de datos de sistemas físicos complejos bajo el mismo grupo societario: cohetes, satélites, coches, robots y millones de enlaces satelitales. Ningún otro jugador de IA está tan cerca de entrenar modelos donde texto, código y telemetría física compartan el mismo embedding.
Anatomía de Colossus el cerebro terrestre de Grok
Antes de conectar Grok con órbita, vale la pena diseccionar dónde vive hoy.
Topología de hardware y red
El supercomputador Colossus, descrito en material de Supermicro y en varios reportajes, tiene una arquitectura bastante clásica de entrenamiento de LLMs, pero llevada al extremo:
GPUs:
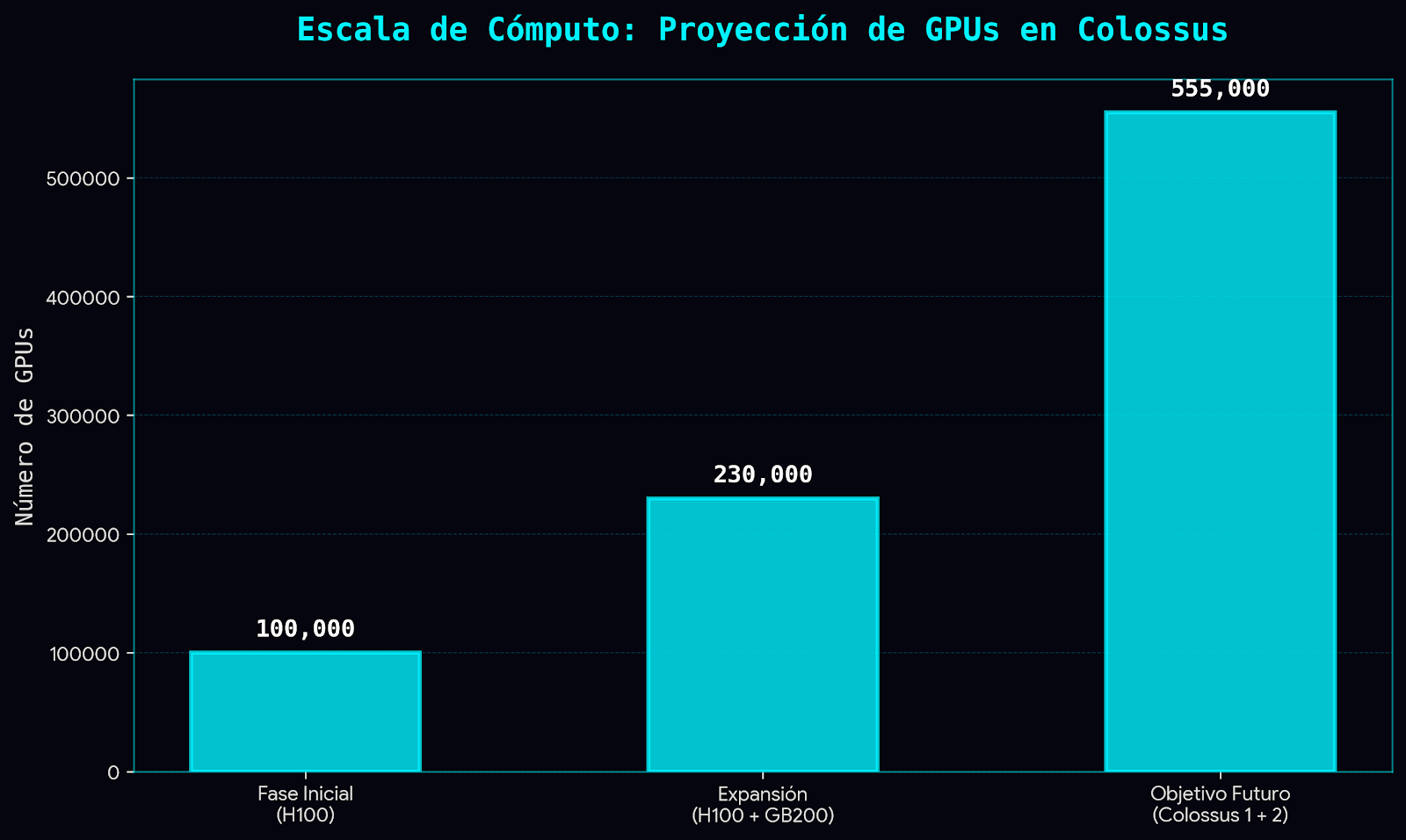
Fase inicial: ~100 000 GPUs NVIDIA H100 (HGX), montadas en servidores 4U de 8 GPUs.
Fases de expansión: hacia 200–230 000 GPUs combinando H100 y Blackwell (GB200), con planes de llegar a ~555 000 GPUs y ~2 GW entre Colossus 1 y Colossus 2 en Memphis.
Nodos:
Servidores 4U Supermicro “liquid‑first”: 8× H100 + 2× CPUs x86, con cuatro switches PCIe Broadcom integrados y refrigeración líquida directa a chip.
Grupos de 8 servidores + CDU redundante (Coolant Distribution Unit) formando racks de 64 GPUs, con manifold frontal para distribución de fluido.
Red:
Cada servidor GPU: hasta 9 enlaces de 400 GbE (≈3.6 Tbps) sobre NIC BlueField‑3 y switches Spectrum‑X, configurados en fabrics RDMA‑over‑Ethernet de muy baja latencia.
Red aparte a 400 GbE para tráfico de CPUs/servicios, separando plano de datos de entrenamiento del plano de control.
Almacenamiento:
Nodos NVMe de alta densidad, mayoritariamente flash, apuntando a capacidades de exabytes para datasets mixtos (texto, código, imágenes, vídeo, logs…).
No hay magia exótica: es un supercluster de LLM estándar, pero empujado a límites de densidad y potencia que pocas empresas pueden costear.
Refrigeración líquida: ingeniería real vs mitología Raptor
En redes ha circulado la narrativa de que el sistema de refrigeración de Colossus usa “tecnología derivada de los inyectores de Raptor”. Técnicamente suena sexy —flujo criogénico a través de microcanales, mixing optimizado, control extremo de gradientes térmicos—, pero lo que sí está documentado es más convencional (aunque igual de impresionante):
Refrigeración directa a chip (D2C):
Bloques de refrigeración personalizados en cada GPU y CPU, con fluido (agua o mezcla) circulando a través de microcanales en contacto directo con el silicio.
Módulos de red PCIe y switches con sus propios bloques, integrados en la misma loop líquida.
CDUs por rack:
Cada rack incorpora una CDU redundante con bombas y alimentación hot‑swap, intentando mantener flujo y presión estables aunque una bomba falle.
Manifolds 1U frontales separan input/output (frío/caliente) a cada servidor, con el clásico código azul/rojo.
Rear‑door heat exchangers:
Como un radiador de coche a escala rack, en la parte trasera, para extraer el calor residual (DIMMs, PSUs, NICs) vía un loop secundario de agua que conecta con la planta de chillers.
Infraestructura de sitio:
Tuberías de gran diámetro para agua fría/caliente cruzando la nave industrial.
Integración con Tesla Megapacks para suavizar picos de carga durante los entrenos, reduciendo estrés sobre la red eléctrica local.
🕵️♂️ The Hidden Layer: En ninguna descripción técnica creíble aparece el uso explícito de componentes o diseños derivados de inyectores Raptor. La analogía conceptual —distribuir flujos uniformes en cientos/miles de microcanales bajo restricciones de presión/cavitación— es válida, pero, a día de hoy, sigue siendo metáfora, no arquitectura reutilizada.
Energía, emisiones y agua, los limites terrestres
Colossus no solo empuja límites de cómputo; también empuja los de energía y medio ambiente:
El sitio de Memphis se alimenta en parte con turbinas de gas propias, muchas instaladas antes de tener todos los permisos necesarios, lo que ha derivado en demandas de NAACP y grupos ambientales.
Los permisos concedidos permiten operar al menos 15 turbinas entre 2025 y 2030, con emisiones significativas de NOx, CO, PM y formaldehído. Informes locales apuntan a decenas de toneladas/año de contaminantes, preocupando a comunidades cercanas.
Con expansiones previstas hacia 1–2 GW, la planta requiere millones de litros de agua al día para cooling; xAI ha prometido sistemas avanzados de recirculación, pero la escala sigue siendo masiva para una ciudad como Memphis.
🕵️♂️ The Hidden Layer:Este muro de energía/agua/aceptación social en tierra es, en la práctica, uno de los motivadores más fuertes detrás de la narrativa “llevemos los data centers al espacio”.
Starlink y los orbital data centers
La otra mitad del sistema es la red. SpaceX no solo tiene cohetes; tiene una de las mega‑constelaciones de comunicaciones más grandes de la historia.
Edge computing en LEO (Low Earth Orbit): lo que ya existe
Antes de ver los planes de SpaceX, conviene mirar el estado del arte en edge computing espacial:
Misiones experimentales de ESA, NASA y JPL ya han volado modelos de deep learning on‑board:
Clasificación de imágenes satelitales.
Segmentación de nubes e inundaciones.
Detección de anomalías en sensores.
Se han usado SoCs comerciales (Snapdragon), VPUs (Intel Movidius MyriadX) y, en algunos casos, FPGAs, logrando:
Reducir drásticamente el volumen de datos raw enviados a tierra (se bajan detecciones/eventos en lugar de imágenes completas).
Acortar el tiempo de respuesta de horas/días a minutos para ciertas alertas.
En el mundo terrestre, la combinación Starlink + edge también se está consolidando:
Proyectos como Armada combinan antenas Starlink con clusters locales (GPU/CPU) para correr inferencia en campo (minería, defensa, energía, emergencias) con backhaul satelital, evitando depender de fibras frágiles.
Lo importante: ya hay un patrón probado de “procesar donde ocurren los datos”, tanto en órbita como en el borde terrestre. SpaceX quiere escalarlo a muchos órdenes de magnitud más.
El sistema de Orbital AI Data Centers de SpaceX
La solicitud de SpaceX ante la FCC para su “Orbital Data Center System” es sorprendentemente explícita:
Hasta 1 000 000 satélites en órbita baja, organizados en múltiples shells (alturas diversas), con enlaces láser inter‑satélite (ISLs) de alta capacidad.
Alimentación primaria por grandes arrays fotovoltaicos y bancos de baterías; cada satélite sería esencialmente un nodo de data center alimentado por el sol.
Función principal: ejecutar cargas de trabajo de IA (entrenamiento e inferencia) en órbita, reduciendo la necesidad de construir macro‑data centers en tierra.
Integración explícita con Starlink:
Uso de la malla satelital existente para backhaul.
Procesamiento de datos en órbita antes de su envío a estaciones de tierra.
Posibilidad de enrutar resultados directamente a usuarios Starlink como parte del servicio.
Varios análisis coinciden en que, en el corto plazo, SpaceX probará estos conceptos usando hardware Starlink V3 con cargas de inferencia relativamente ligeras, antes de lanzar satélites dedicados más masivos.
¿Starlink como “GPU mesh” planetaria?
Conviene matizar la narrativa de marketing:
Hoy:
Starlink sirve como red de transporte y acceso.
Grok está integrado como chatbot de soporte para clientes de Starlink, pero toda la inferencia vive en data centers terrestres como Colossus.
Los satélites tienen CPUs/ASICs para RF, routing y control, pero no aceleradores de IA de propósito general para tus workloads.
Mañana (visión declarada):
Una constelación mixta donde:
Satélites tipo Starlink siguen proporcionando conectividad.
Satélites de data center dedicados (más grandes, más pesados, con radiadores descomunales) alojan racks de cómputo de IA.
Nodos edge en tierra (Armada, gateways, clientes enterprise) actúan como “hojas” del árbol de cómputo.
Dicho esto, desde un punto de vista de sistema distribuido, si asumes:
Un millón de nodos en LEO con capacidades heterogéneas de cómputo.
Un fabric óptico mesh de baja latencia entre ellos.
Una red de estaciones y edge nodes alimentados por Starlink.
lo que obtienes se parece mucho a una GPU mesh planetaria, aunque físicamente esté repartida entre órbita y superficie. Los principales retos aquí serán la orquestación (quién corre qué, dónde y cuándo) y el problema termodinámico, del que casi nadie habla.
Suscríbete para que juntos destapemos las cajas negras y descubramos lo que ocultan.
¿Cómo disipar megavatios en el vacío?
La narrativa “en el espacio hace frío, así que el cooling es gratis” pero esto es física de Twitter, no de ingeniería. Varios análisis técnicos independientes lo han señalado de forma tajante:
En el vacío no hay convección ni conducción con el entorno; la única vía de disipación térmica es la radiación (P∝T4P∝T4).
Operar chips a temperaturas típicas de data center (60–80 °C) implica una potencia radiada por unidad de área relativamente baja, por lo que se necesitan radiadores enormes:
Estimaciones gruesas hablan de superficies del orden de cientos de metros a kilómetros cuadrados para disipar varios MW por satélite a temperaturas operables.
Esto impacta:
Masa: radiadores grandes = satélites pesados = más coste de lanzamiento (aunque Starship abarate mucho €/kg).
Complejidad mecánica: estructuras desplegables, articulaciones, control térmico activo.
Control de actitud: radiadores deben orientarse para evitar insolación directa y gestionar gradientes térmicos.
Mientras tanto, en tierra, Colossus “solo” tiene que mover agua, usar chillers y torres de enfriamiento, y pelear con la comunidad y la factura de luz. Es duro, pero está en el dominio conocido de HVAC industrial.
La conclusión aquí es importante: el cuello de botella de los orbital data centers no es el lanzamiento ni la energía solar, sino la ingeniería térmica en el vacío. Cualquier análisis serio de viabilidad tiene que empezar por ahí, no por el costo del kWh o el capex por GPU.
System design de la singularidad SpaceX–xAI
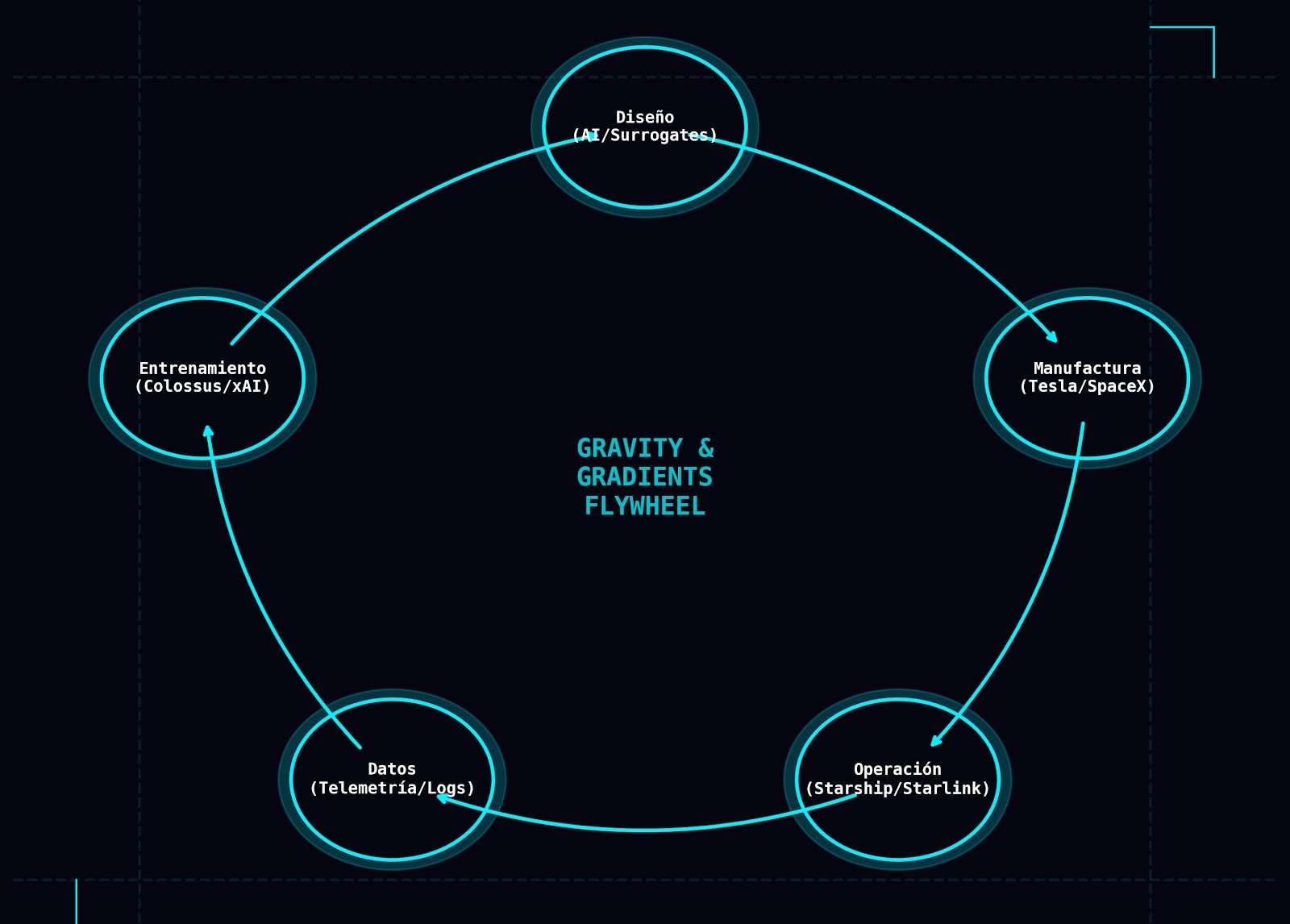
Con los ingredientes sobre la mesa —Colossus, Starlink, orbital data centers, telemetría física—, se puede bosquejar una arquitectura “Gravity & Gradients” que razone más allá del titular.
Capas del stack
Piensa el sistema como un multi‑tier improbable:
Capa de percepción física
Cohetes y naves: Falcon, Starship, Dragon.
Satélites: Starlink, Starshield, futuros sats de data center orbital.
Robots y vehículos: Tesla, Optimus, infraestructura de tierra de SpaceX.
Capa de red y transporte
Malla satelital Starlink (ISLs ópticos + RF a usuarios).
Enlaces láser entre sats de data center.
Estaciones de tierra y nodos edge (Armada, gateways propios, centros de datos regionales).
Capa de cómputo
Terrestre:
Colossus (entrenamiento, fine‑tuning masivo, orquestación).
Data centers regionales/edge enterprise.
Orbital:
Nodos de data center dedicados (entrenamiento incremental, inferencia intensiva ligada a datos orbitales).
Capacidades de inferencia ligera en sats Starlink/Starshield.
Capa de modelos
LLMs generalistas (Grok 4/5) como “cerebro de alto nivel”.
Modelos especializados:
GN&C asistido por ML.
Surrogates de CFD/FEA.
Modelos de red para optimizar capacidad y calidad de servicio.
Modelos de visión y planificación para robots y vehículos.
Capa de agentes y productos
Agentes de soporte (Starlink, Tesla).
Agentes de operations (gestión autónoma de constelaciones, scheduling de lanzamientos, planificación logística).
Interfaces humanas (X, apps, APIs corporativas).
El loop de entrenamiento cerrado
Dentro de esa arquitectura, emerge de forma casi inevitable un loop de datos–modelo–acción. Simplificando mucho:
Diseño asistido por modelos
Ingenieros de SpaceX usan herramientas potenciadas por xAI para diseñar nuevas iteraciones de Raptor, estructuras de Starship, satélites de data center.
Bajo el capó, hay surrogates ML entrenados sobre:
Simulaciones CFD/FEA existentes.
Datos de vuelo históricos.
Fabricación y despliegue
Tesla y las fábricas de SpaceX manufacturan esos diseños optimizados.
Starship los lleva al espacio: satélites, módulos de data center orbital, nuevos segmentos de la constelación.
Operación y observabilidad
Los sistema operan:
Cohetes vuelan y aterrizan.
Sats rutéan tráfico y corren modelos.
Robots construyen infraestructura, coches circulan.
Todo genera telemetría continua y logs de eventos (incluyendo fallos, casi‑fallos, anomalías raras).
Ingesta y entrenamiento
xAI ingiere esas corrientes de datos:
Actualiza surrogates con datos de vuelo reales (continual learning, domain adaptation).
Re‑entrena modelos de control, diagnóstico y optimización.
Alimenta a Grok con corpora enriquecidos de explicaciones técnicas, incident reports, documentación y resúmenes generados.
Nueva iteración de diseño y operación
Los modelos mejorados se usan para:
Diseño de la siguiente iteración de hardware.
Ajuste de parámetros operativos (perfiles de vuelo, scheduling de satélites, asignación de cargas de trabajo de IA).
El ciclo se repite.
Este patrón es una extrapolación del bucle Tesla FSD (datos de flota → modelo → actualización OTA → nuevos datos de flota) a la escala de una infraestructura aeroespacial completa.
¿Dónde corren los modelos?
En este sistema, el “dónde” de los gradientes importa:
Entrenamiento base:
Lo más probable es que el pretraining de modelos grandes (Grok N) siga ocurriendo en tierra, en Colossus y otros sites: la complejidad de cooling, mantenimiento y actualización de hardware es mucho más manejable.
Entrenamiento incremental / fine‑tuning cercano a la fuente:
Para tareas muy ligadas a datos orbitales (ej. detección de patrones atmosféricos, dinámica de basura espacial), tiene sentido entrenar o ajustar modelos directamente en nodos orbitales, usando datos que nunca bajan a tierra.
Inferencia:
Inferencia de baja latencia y dependiente de posición/tiempo (p. ej. reaccionar a fenómenos locales, planificar observaciones) puede vivir en edge orbital.
Inferencia que interactúa con humanos (chat, copilots) probablemente seguirá sirviéndose desde tierra, por cercanía a los usuarios y mejor integración con sistemas legacy.
Orquestar esto es un problema de scheduling distribuido bajo constraints físicos: ventanas de visibilidad, latencias variables, energía limitada, cooling por radiación. Es un playground perfecto para agentes de alto nivel (Grok/LLMs) coordinando swarms de modelos especializados.
¿Por qué este stack es difícil de imitar?
Visto en conjunto, SpaceX–xAI no es solo “otra empresa de IA con muchos GPUs” ni “otra compañía espacial con cohetes reutilizables”. Es un intento deliberado de construir un circuito cerrado entre materia, energía, información y optimización:
Gravedad:
Starship, cohetes, satélites y robots están anclados a leyes físicas que no negocian: ecuaciones de Navier‑Stokes, termodinámica, mecánica orbital.
SpaceX controla la cadena logística de acceder al espacio y desplegar masa a bajo coste.
Gradientes:
Colossus y sus sucesores son máquinas dedicadas a minimizar funciones de pérdida en espacios de parámetros gigantes.
xAI, a diferencia de otros labs, puede definir pérdidas donde aparecen directamente magnitudes físicas medibles: probabilidad de fallo de un Raptor, throughput de Starlink bajo tormenta geomagnética, tiempo medio de reparación de una falla de usuario.
Datos:
X, Tesla, Starlink, SpaceX y, en el futuro, robots Optimus aportan streams de datos multimodales (texto, vídeo, telemetría, audio, sensores estructurales) bajo la misma galaxia corporativa.
La actualización de políticas de privacidad de Starlink muestra claramente la intención de aprovechar esa ventaja.
Lo que hace singular este stack no es un solo componente, sino la superposición de gravedad y gradientes:
🕵️♂️ The Hidden Layer: Donde otros laboratorios entrenan modelos sobre un mundo discretizado en palabras e imágenes, SpaceX–xAI aspira a entrenarlos sobre un mundo donde cada token puede estar anclado a una fuerza, una órbita, una vibración, una caída de tensión o un microfallo en un enlace láser.
Replicar esto exige algo más que dinero:
Lanzadores reutilizables de gran capacidad.
Mega‑constelaciones operativas.
Infraestructura de supercómputo de escala nacional.
Productos de consumo que generen datos y flujo de caja (coches, robots, conectividad, plataformas sociales).
Por eso, nos guste o no, la fusión SpaceX–xAI es algo más que un titular de “Musk arma su propio OpenAI”.
Es el primer intento serio de hacer que la ingeniería aeroespacial, la infraestructura de red y la IA compartan no solo un balance general, sino también un mismo espacio de representación.
Y ahí es donde todo cobra sentido: Starship necesita un cerebro y Grok, por primera vez, tiene un cuerpo que sentir, pilotar y optimizar.
¿Crees que la disipación térmica en el vacío será el muro con el que choquen, o es un problema soluble?
Me gustaría saber tu opinión, no olvides comentar o enviar un correo con tu opinión o contarme que otros temas te gustaría que aborde.
📚 Glosario fp32
Cooling Radiativo ($P \propto T^4$): En el vacío no hay aire para llevarse el calor (convección). La única forma de enfriar algo es emitir luz infrarroja. Es mucho menos eficiente y requiere paneles gigantes.
Backhaul: La conexión “trasera” que une la red de acceso (tu antena Starlink) con el núcleo de internet. Aquí, el backhaul sería láser entre satélites.
Surrogate Models: Modelos de IA ligeros que aprenden a imitar simulaciones físicas complejas (como CFD) para dar resultados en milisegundos en lugar de horas.